
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- pandas 조건
- 비선형함수 딥러닝
- pandas 행 제거
- pandas row 제거
- 모델 freeze
- pandas
- pytorch 데이터셋 나누기
- Skip connection
- Graph Theory
- Does GNN Pretraining Help Molecular Representation?
- 일부 레이어 고정
- pandas 특정 조건 열 제거
- python 경우의 수
- molecular representation
- layer 일부 freeze
- sktime tutorial
- pytorch dataset split
- sktime 튜토리얼
- 선형함수 딥러닝
- EDA 추천 파이썬
- pretraining
- 경우의 수 파이썬
- sktime
- 판다스 조건
- Prompt Tuning for Graph Neural Networks
- 비선형함수
- weight 일부 고정
- 시계열 라이브러리
- EDA in python
- sktime 예제
- Today
- Total
MoonNote
Contrastive Self-supervised Learning for Graph Classification 본문
Contrastive Self-supervised Learning for Graph Classification
Kisung Moon 2021. 12. 8. 21:293줄 요약
- graph-level에서 Contrastive self-supervised learning(CSSL)을 적용한 논문
- node나 edge의 변경을 통해 augmentation한 positive pair를 구성하는 방식으로 contrastive learning을 진행함
- 기존 접근법 이외에, CSSL loss를 graph classification loss에 추가한 regularization을 적용하여 성능 향상을 이끌어냄
Background & Introduction
- 비전 분야에서 특히 효과적으로 활용되고 있는 CSSL을 graph 분야에 사용한 논문이다.
- 비전에서는 random crop, 색 변경, 회전 등으로 CSSL의 positive pair를 구성하는데, graph에서는 어떻게 구성할지에 대해서 살펴본다.
- 이전에 나왔던 graph에 SSL을 적용한 논문들은 node나 subgraph와 같은 local한 element들의 표현에 집중하였고, 본 논문에서는 graph classification과 같은 graph-level의 representation에 집중한다고 한다.
Methods
- 본 논문에서는 두 가지 종류의 CSSL 방법을 제안한다. 첫 번째는 일반적인 방법처럼, unlabeled graph에 graph encoder를 pretrain 후 labeled graph에 finetune을 진행한다. 두 번째 방법은 CSSL 기반의 regularizer를 개발하여, supervised graph classification task와 unsupervised CSSL task를 동시에 진행한다.
- 첫 번째 방법을 CSSL-Pretrain, 두 번째를 CSSL-Reg로 나타낸다.
- 논문에서는 In CSSL-Pretrain, we use CSSL to pretrain the graph encoder. In CSSL-Reg, we use the CSSL task to regularize the graph encoder. 으로 표현하고 있다.
- CSSL에서는 original graph에서 augmentation된 graph가 같은 original graph에서 생성되었는지 아닌지로 network를 훈련한다. 크게 4가지 augmentation 방법을 사용하였다.
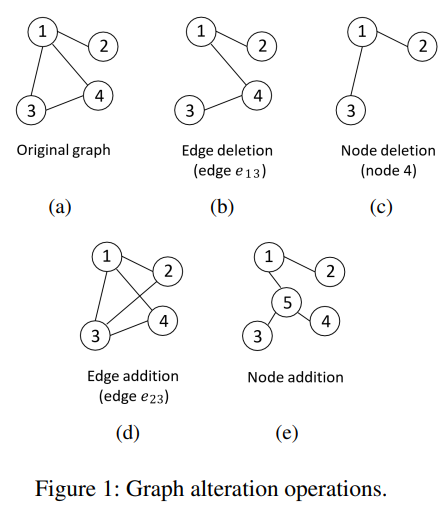
사용된 augmentation 네 가지
1. Edge deletion
- random하게 edge를 선택 후, 제거한다.
2. Node deletion
- random하게 node를 선택 후, 제거한다. node와 연결되어있던 edge들도 같이 제거된다.
3. Edge addition
- two node가 직접적으로 연결은 안 되어있지만 path가 존재하면 random하게 선택 후 추가한다.
4. Node addition
- strongly-connected subgraph S를 random하게 선택 후, S의 edge를 모두 제거한다. 그리고 새로운 node를 추가한 후, S안의 모든 node와의 edge를 추가한다.
CSSL-based Pretraining
- 일반적인 CSSL 방법으로 진행한다.
CSSL-based Regularization
- CSSL task를 graph classification을 regularize 하기 위해 사용한다.
- CSSL task의 loss가 overfitting을 완화하기 위한 data-dependent regularizer의 역할을 한다.
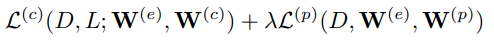
- $D$: training graph
- $L$: label
- $W^{(e)}$, $W^{(c)}$, $W^{(p)}$: graph encoder, classification head in classification, prediction head in CSSL
- $L^{(c)}$: classification loss, $L^{(p)}$: CSSL loss, $\lambda$: tradeoff paramter
Results
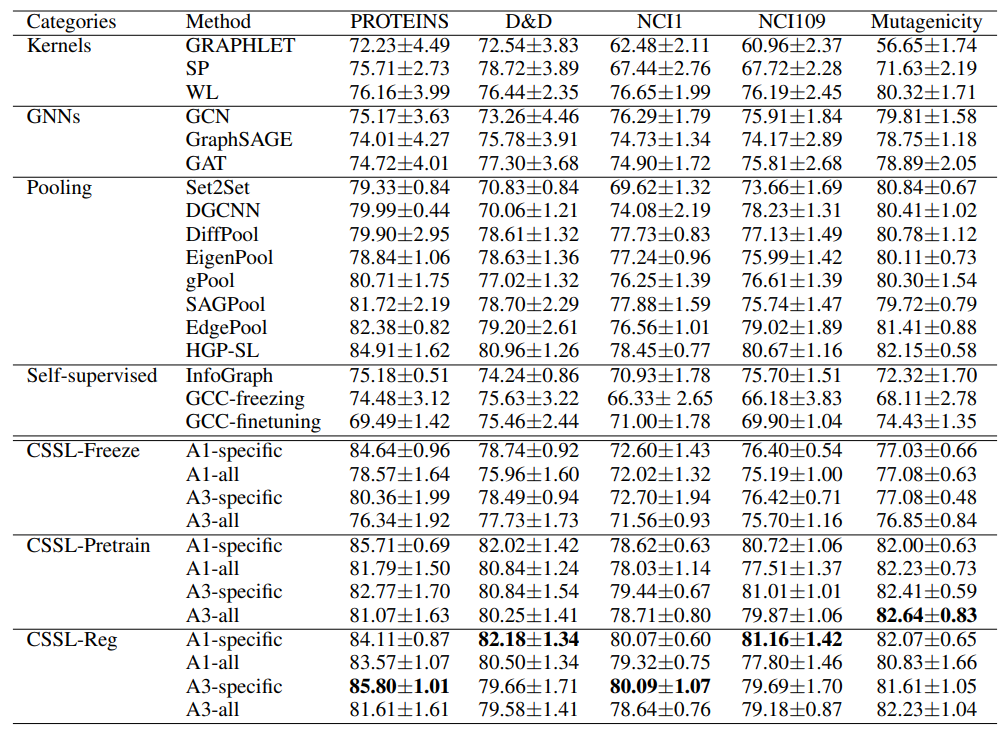
- "A1"은 augmentation 중 하나를 random으로 사용한 것, "A3"은 augmentation 중 세 개를 random으로 사용한 것
- "Specific"은 CSSL loss를 정의하기 위해 target dataset을 사용한 것, "ALL"은 5개의 dataset을 사용한 것
- 실험 결과, CSSL-Reg가 가장 우수한 성능을 보였다.

