
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- EDA 추천 파이썬
- pandas
- Prompt Tuning for Graph Neural Networks
- python 경우의 수
- weight 일부 고정
- EDA in python
- 비선형함수
- pytorch 데이터셋 나누기
- Graph Theory
- 모델 freeze
- sktime tutorial
- sktime 예제
- 경우의 수 파이썬
- pandas 조건
- 일부 레이어 고정
- Skip connection
- Does GNN Pretraining Help Molecular Representation?
- sktime
- layer 일부 freeze
- 비선형함수 딥러닝
- pandas 행 제거
- pretraining
- 시계열 라이브러리
- pytorch dataset split
- 선형함수 딥러닝
- sktime 튜토리얼
- pandas 특정 조건 열 제거
- molecular representation
- pandas row 제거
- 판다스 조건
- Today
- Total
MoonNote
Does GNN Pretraining Help Molecular Representation? 본문
Does GNN Pretraining Help Molecular Representation?
Kisung Moon 2023. 5. 23. 23:06https://arxiv.org/pdf/2207.06010.pdf
NeurIPS 2022에 accpet 되었고 Google Research 팀에서 쓴 논문이다.
제목부터 흥미가 가고 내용도 수학적인 부분보다는 실험적인 내용이라 읽기에 부담스럽지는 않았던 것 같다.
개인적으로 나도 molecular gnn으로 pretraining에 관한 연구를 했었기 때문에 어떤 내용일까 궁금했다.
3줄 요약
1. 2D-GNN (GIN, SAGE)을 사용하여, molecular representation에 대한 pretraining의 효과를 심도 있게 분석함
2. 알고 있던 통념과 다르게, pretraining의 효과는 미미한 것으로 나타남. 기존 연구들은 사실 cherry-picking 한 부분이 없지 않아 있다는 말
3. NLP에서의 pretraining의 성공과 비교하여, pretraining이 언제 효과가 있는지, 그리고 효과가 사라지는지를 분석함
Abstract
- NLP 분야에서의 self-supervised learning이 상당히 주목받고 놀라운 결과를 보여줬었는데 이를 graph 분야에도 적용해보려는 시도들이 있었다.
- 하지만 저자들은 small molecular data에서는 pretraining의 이득이 미미하다는것을 발견했다.
- 다양한 ablation study (pretraining objectives, data splitting methods, input features, pretraining dataset scales, GNN architectures) 를 통해 SSL이 downstream task에 미치는 영향을 파악했다.
- 가장 중요한 첫번째 발견으로는 SSL이 non-pretraining에 비해 항상 통계적으로 유의미한 이점을 가지지는 않는다는 것이다.
- 두번째는 SSL로 인해 improvement가 있더라도 더 rich한 feature나 balanced data splits로 성능 향상이 줄어들 수 있다.
- 셋째는 특히 downstream의 scale이 작을 때 (무슨말??) hyperparameter가 pretraining task의 선택보다 더 큰 영향을 미칠 수 있다.
- 마지막으로, small molecule에 대한 일부 pretraining 방법의 complexity가 충분하지 않다는 추측과 다양한 pretraining dataset에 대한 경험적인 증거를 보여준다.
1. Introduction
- 본 논문에서는 social networks, citation graphs 등 다른 도메인 말고 small molecular domain에만 연구 범위를 제한한다고 한다.
- 본 논문의 key insight는 다음과 같다.
1. 평가한 pretraining task 중 self-supervised pretraining 만으로는 downstream task에서 pretraining 되지 않은 방법에 비해 통계적으로 유의미한 개선을 제공하지 않는다.
2. self-supervised pretraining 후에 additional supervised pretraining step을 진행하면 통계적으로 유의미한 개선이 관찰된다. 그러나 일부 특정 data split에서는 개선이 미미해지거나 더 rich한 feature가 도입되면 감소한다.
3. data splits 및 hand-crafted features 외에도 graph pretraining의 이득은 learning rate 및 반복 실험 횟수와 같은 실험적 hyperparameter에도 민감합니다. 설정이 다르면 반대의 결론이 나올 수 있다.
4. 결론적으로, 이전 연구와 달리 우리는 graph pretraining에 의해 달성된 명확하고 무조건적인 이득을 관찰하지 못했으며, 이는 graph pretraining이 molecular domain에서 효과적이라고 결론짓기에는 아직 이르다는 것을 나타낸다.
5. 우리는 위의 이유를 조사하고 분자에 대한 일부 pretraining method의 complexity이 불충분하여 downstream task에 대한 transferable knowledge가 적다는 가설을 세운다.
Despite the overall negative results we obtained, the main goal of this paper is not to discourage the pretraining research for small molecules. Instead, we hope to raise attention to different aspects of experiments and the role of simple hand-crafted features, so as to provide useful information for designing better pretraining approaches.
이런 문장들이 google스럽게 잘 쓴 문장이라고 생각한다. 나도 이렇게 쓰고 싶다..
2.1 Self-supervised (unsupervised) pretraining
2.1.1 Node Prediction
- Node prediction은 atom을 masking 한 후에 그것의 feature를 예측하는 task라고 보면 된다.
2.1.2 Context Prediction
- Context prediction은 sub-graph level task이다. node 주변의 local subgraph를 파악해서 비슷한 context를 가진 node를 비슷하게 embedding 한다. (확실하지 않음, Hu et al. STRATEGIES FOR PRE-TRAINING GRAPH NEURAL NETWORKS 논문 참고)
2.1.3 Motif Prediction
- Motif prediction은 functional groups 존재 여부를 예측하는 graph-level multi-lable binary classification task이다.
2.1.4 Contrastive Learning
2.2 Supervised pretraining
- Supervised pretraining은 특별히 설계된 pretraining task에서 domain-specific graph-level knowledge을 학습하는 것을 목표로 합니다.
3 Experiment framework
- Figure 1에 전체적인 과정이 나타나있다.

- The design principle of our experiment framework is to analyze the effect of every stage in the pipeline as comprehensive as possible, while also keeping it tractable to avoid exponentially many experiments.
3.1 Design choices
Graph Features
ㅇ Basic features.
- basic feature는 Hu et al.에서 참고함. 예를 들어, atom type and the derived features, such as formal charge list, chirality list, etc.
ㅇ Rich features.
- rich feature는 basic feature의 상위 set이다. additional node features such as hydrogen acceptor match, acidic match and bond features such as ring information.
Pretraining dataset
ㅇ ZINC15 (2 million)
ㅇ SAVI (1 billion)
ㅇ ChEMBL (500k + 1,310 prediction target labels): graph-level의 supervised pretraining을 위해서만 사용
Data split on downstream tasks
Scaffold Split
- molecule을 scaffold에 따라 정렬한 다음 연속적으로 train/valid/test 으로 나눈다.
- 따라서 train set과 test set은 분자 구조에 따라 가장 다른 분자이다. 이 방법은 deterministic data splits을 생성한다.
Balanced Scaffold Split
- 위의 sorting 및 splitting 단계에서 randomness을 도입하므로 다른 random seed가 있는 분할에서 실행하고 average performance을 나타내어 evaluation variance을 낮출 수 있다.
- 본 논문에서는 bias를 피하기 위해 Balanced Scaffold Split로 주로 평가했다고 한다.
3.2 Experiment protocol







- 3 random seed의 평균 성능 측정
- learning rate를 {1e −4 , 5e −4 , 1e −3 , 5e −3 , 1e −2 , 5e −2 , 1e −1} tuning하며 개별적으로 최고의 성능 선택
- hidden dimenstion을 300으로 고정하고 5 layer를 사용
4. Results
4.4 Data split on downstream tasks
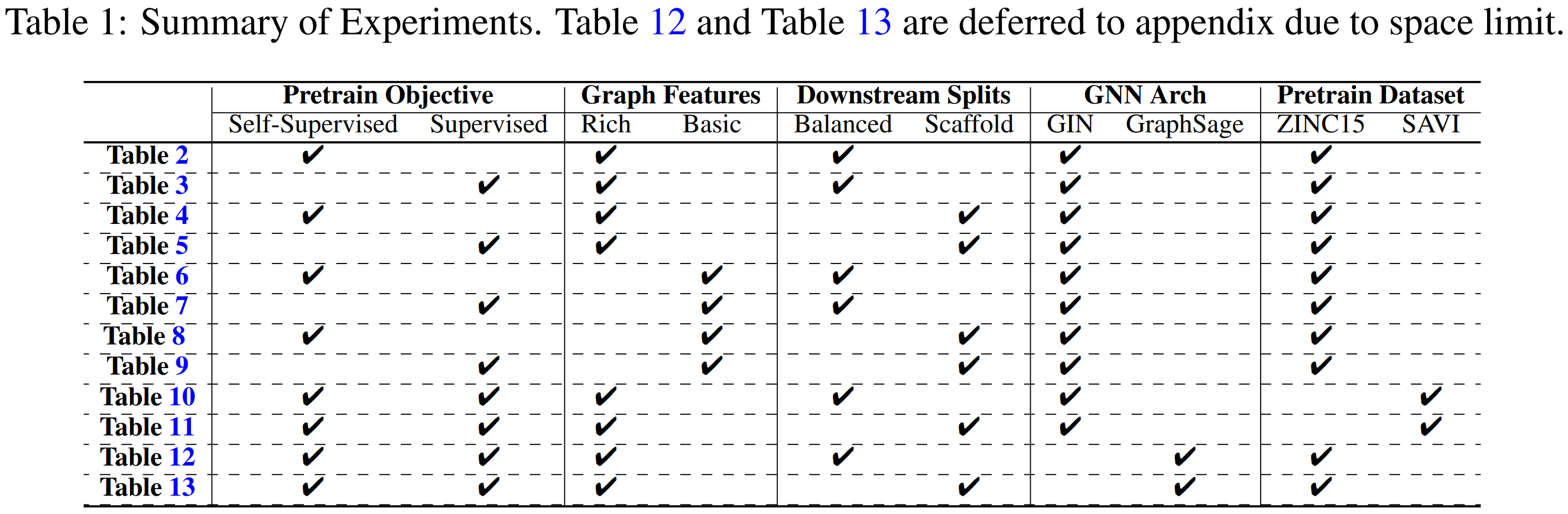
- Table 2와 4, Table 3과 5를 비교해보자. split 방법에 따라서 pretrainig의 효과가 다른 것을 볼 수 있다.
- balanced scaffold 보다 scaffold spit에서의 효과가 더 좋다.
- 여기서 추측할 수 있는 점은 out-of-distribution generalization (e.g. scaffold split)에서 parameter의 initialization이 더 중요하다는 사실이다.
4.5 Graph features
- self-supervised learning의 효과보다 rich한 feature를 추가하는 효과가 더 좋았다.
- supervised pretraining의 효과는 항상 좋았다. 즉 downstream task과 관련있는 supervision을 사용했기 때문에 일관성과 신뢰성을 보여줍니다.
Our hypothesis is that, supervised pretraining is helpful when the pretraining tasks are closely aligned with the downstream tasks. In particular, the bio-activity labels provided by ChEMBL is highly related to the drug discovery purpose and drug discovery properties are the major topics evaluated in the downstream tasks. Therefore, the positive correlation between the pretraining supervision and downstream tasks contribute the most to the performance improvement of downstream tasks.
4.6 Pretraining datasets


- 충격적이게도, ZINC15 vs SAVI dataset으로 pretraining한 결과를 비교해봤는데 큰 차이가 없었다.

- SAVI로 pretraining할 때, 정확도가 1 epoch이 되기도 전에 90%에 육박한다. 이는 큰 규모의 데이터셋을 사용하더라도 모델에게 많은 learning signal을 제공하지 않는다는 것을 의미한다.
- 또한, 왜 self-supervised pretraining이 몇가지 상황에서 그렇게 효과적이지 않은지에 대한 이유를 제시한다.
ㅇ Tasks are easy.
- masked node prediction의 경우를 보면, 100개보다 적은 후보 atom 중 하나를 예측하는 task이다. 또한, valence constraints 때문에, graph topology은 이미 대부분의 잘못된 atom들을 배제할 수 있다.
- text pretraining의 vocabulary size는 100k 그 이상일 수 있다.
- structured prediction 자체의 어려움 때문에 context prediction과 같은 일부 structured prediction task은 어려울 수 있다. (그나마 어려워서 self-supervised 중에서는 좋지만 task 자체가 힘들어서 항상 좋지는 않다는 뜻 같음)
- contrastive learning에서 high quality negative example의 생성은 여전히 challenge하다.
- motif prediction은 subgraph matching를 통해 달성할 수 있으며, 이는 본질적으로 graph isomorphism test를 수행하는 GNN에서 쉽게 수행할 수 있다.
ㅇ Data lacks diversity.
- biophysical 및 functional requirements으로 인해 분자는 많은 공통 sub-structures(예: functional motif)를 공유한다.
- 따라서 분자는 텍스트 데이터만큼 다양하지 않을 수 있다. 이것이 모델이 training distribution 내에서 빠르게 일반화하는 법을 배우는 이유이다.
ㅇ 2D Structure is not enough to infer functionality.
- 일부 중요한 biophysical properties(예: 3D structure, chirality)은 2D-feature-based pretraining(예: smiles 또는 2D graph features 사)에 거의 반영되지 않는다.
- 예를 들어, 동일한 화학식과 2D 특징을 가진 분자는 매우 다른 chirality을 가질 수 있으며, 이는 상당히 다른 독성[24](예: flipped toxicity labels)으로 이어집니다. 이것은 우리가 고려한 현재 GNN pretraining framework에서 캡처되지 않는다.
4.7 Hyper-parameters for downstream tasks
- 저자들은 downstream task에 대한 hyper-parameter가 성능에 매우 중요하며 해당 선택이 pretraining의 효과에 대한 결론을 변경할 수 있음을 발견했다. 학습률을 예로 들 수 있다. 처음부터 초기화된 모델과 pretraining이 서로 다른 scale을 가질 수 있으므로 downstream task에 가장 적합한 learning rate도 다를 수 있다.
- learning rate를 extensively하게 조정하지 않으면 잘못된 결론에 도달할 수 있다. 특히 Appendix A.4의 Table 17에서 기존의 pretraining을 재현하기 위해 기본 learning rate를 사용하면 실제로 pretraining의 이점을 관찰한다.
- 그러나 우리의 절차(예: extensive search learning rate 및 averaging over three splits)를 따르면 Table 2 및 Table 3은 pretraining을 통해 성능이 향상되지 않음을 나타낸다. 따라서 우리는 pretraining의 평가에서 hyper-parameter 튜닝과 다른 splits에 대한 평균을 고려해야 한다고 제안한다.
5 Summary and takeaways
When pretraining might help
1) downstream task와 positive correlation를 가진 supervised pretraining with target labels을 가지고 있을 때 도움이 된다. 하지만, high-quality의 관련 supervision을 많이 받는 것이 항상 feasible한 것은 아니다.
2) high quality hand-crafted feature가 없는 경우. 하지만 self-supervised pretraining 얻는 성능 향상은 high quality hand-crafted features 만큼 중요하지 않은 것 같다.
3) downstream task의 train, valid, test dataset 분포가 상당히 다를 때
When the gain diminishes?
1) 이미 high quality hand-crafted feature (즉, rich features)을 가지고 있을 때
2) highly relevant supervision을 하지 않았을 때. Section 4.6에서 볼 수 있듯이, 많은 self-supervised pretraining task들은 model에게 너무 쉬워서 meaningful embedding을 배우기 어렵다.
3) downstream split이 balance 할 때
4) self-supervised learning dataset이 scale에도 불구하고 diversity가 부족할
Why pretraining may not help in some cases?
- much larger dataset (SAVI)를 사용하였을 때, NLP 처럼 성공적인 적용을 기대했지만, 기대했던 효과는 나타나지 않았다.
- Figure 2의 accuracy curve는 왜 pretraining의 효과가 없는지 potential explanation을 제공한다: 상당히 빠르게 수렴해서 95%+의 정확도를 보이지만, NLP에선 70%까지 계속 향상되고 수렴이 잘 이루어지지 않는다.
- 이는 masked node label prediction 같은 pretraining 방법이 쉽기 때문에 (vocabulary size가 NLP와 비교해서 훨씬 작다) knowlege가 잘 trasfer 되지 않는다고 생각된다.
6 Limitations of current study
Although we have tried our best to design a comprehensive study on the effectiveness of graph pretraining for molecular representation, there are still limitations we want to point out. Due to the limited time and resources we have, we are not able to fully cover the whole picture of the current pretraining paradigm in graph neural networks. Nevertheless, we list them here in hope of preventing the over-generalization of our conclusion.
이런 conclusion도 정말 잘 쓴 것 같다.
ㅇ Distribution of graphs.
- 본 연구에서는 small molecule graph inductive representation learning의 pretraining에 집중하였다.
- 최근 large graph에 대한 transductive representation을 pretraining하는 work에서는 우리의 결론이 직접적으로 확장이 되지 않을 수 있다.
ㅇ Graph architectures.
- GNN은 probable expressiveness을 가진 많은 새로운 architectures가 제안되는/제안될 인기 있는 연구 분야이다.
- 본 논문에서 보여준 결과는 두 가지 대표적인 1-WL GNN에 대한 것이다. deep GNN[17]과 Transformer 기반 GNN[34, 3, 14]의 최신 연구에서는 다른 결과를 낳을 수 있다.
ㅇ Learning objectives.
- 서로 다른 유형의 self-supervised loss로 결과를 제시했지만 contrastive learning의 다양한 변형[26, 31]과 같이 탐색하지 않은 각 유형의 variants이 여전히 많이 있다.
- 또한 다양한 self-supervised objectives에 대한 multi-task learning은 further exploration을 위한 또 다른 방향이 될 수 있다.
ㅇ Downstream datasets.
- 본 논문에서는 주로 MoleculeNet의 dataset으로 부터 결론을 얻었지만 Alchemy와 drug-target Interaction 같은 다른 dataset에서는 다른 결과를 보일 수 있다.
Comments
- limitation에서도 이야기하고 있지만, 1) small molecule에만 적용한 점, 2) 2D based GNN만 사용한 점, 3) semantic의 변경을 최소화하는 contrastive learning을 비교하지 않은 점 등의 개선점이 존재함
- 하지만 pretraining이 무조건 효과가 있고, 또 데이터셋이 클수록 효과가 좋을 것이라는 기존 통념을 다시 생각하게 해줌 + 좋지 않은 근거까지 제시
- 정말 좋은 논문이라고 생각하지만 openreview를 보니까 reject을 준 리뷰어들이 있던데 자세히 살펴봐야겠음



